
How to Convert MyISAM to InnoDB in MySQL Stor
MySQL has a range of available storage engines that c...







Duplicate rows, also known as duplicate records, are records containing the same values in one or more columns. These duplicate rows affect the precision of data and can lead to incorrect results if you are analyzing or reporting data. They can also take valuable space in your database hence affecting query performance and also over time can add up to the size of a database.
Duplicate rows are created when data was imported incorrectly, a user did not follow proper data-entry protocols, or possibly due to the lack of primary keys or unique indexes. Duplicate records generate inconsistencies if not rectified but they can affect the way the application is running as well as the reliability of the data in your database.
In this article, we will explore all the ways to locate and remove duplicate rows in MySQL using a number of different techniques. We will be using SQL commands like GROUP BY, ROW_NUMBER()(and other window functions), or using subqueries. Each great method will implement simple examples for you to comprehend and make the solution work in your own database.
The GROUP BY clause, when used with COUNT can be used to discover duplicates in MySQL since it groups rows by one or more columns. COUNT reports how many times each group exists, and if that count is greater than 1, then you know you have duplicate data:
SELECT first_name, COUNT(*) AS count FROM Customers GROUP BY first_name HAVING count > 1;

This method works in all MySQL versions. It is simple and effective for quickly spotting repeated values across selected fields.
ROW_NUMBER is a window function introduced in MySQL 8.0. It assigns each row a number within a group defined by the PARTITION BY clause. When finding duplicates, any row with a row number greater than 1 in the same group is a duplicate.
You can find the duplicate customer names from the Customers table with this query:
SELECT customer_id, first_name, last_name, age, country
FROM (
SELECT customer_id, first_name, last_name, age, country,
ROW_NUMBER() OVER (PARTITION BY first_name ORDER BY customer_id) AS row_num
FROM Customers
) AS temp
WHERE row_num > 1;

This method gives you more leverage than the previous method, and is especially useful when you want to keep one copy and delete the other copies. This selection method works best with larger datasets, as it eliminates the possibility of working with a grouped selection or needing to count records in the grouped selection when filtering the duplicates, and it uses ROW_NUMBER, which can only be used in MySQL 8.0 or higher.
Build Blazing-fast Websites with MySQL Hosting!
Ultahost’s high-performance pre-configured servers ensure fast MySQL websites and apps with easy setup, scalability, and expert support!
Always make a backup first before you delete any duplicate rows. It protects against accidental data loss, should you need to go back to your initial state. Following SQL best practices will have you backing up your data anytime before a delete operation. Here is the guide for the recovery of your MYSQL database, read How to Backup a MySQL Database.
To back up your table you can create a duplicate of it with the CREATE TABLE … SELECT statement. This command will create a duplicate of the table and the data that it currently has without affecting the original. In this case, if you want to back up the Customers table you would run the command:
CREATE TABLE Customers_backup AS SELECT customer_id, first_name, last_name, age, country FROM Customers;
This command will create a new table called Customers_backup with all the data in it. You can now work on the original table and feel comfortable knowing there is a backup table.
In addition to backing up your data with a duplicate table, you can export your MySQL data to a .sql or .csv file to save it offline or to transfer it to other applications. Exporting your data is an additional way to keep your MySQL data safe, especially if you are working on your database. Exporting can also be very useful for a safe delete. Depending on your environment, exporting tools can vary, but all export tools are a valuable addition to a safe delete process.
We will use the updated Customers table below, which contains duplicate rows let’s discuss the methods on how to delete duplicate rows in mysql:
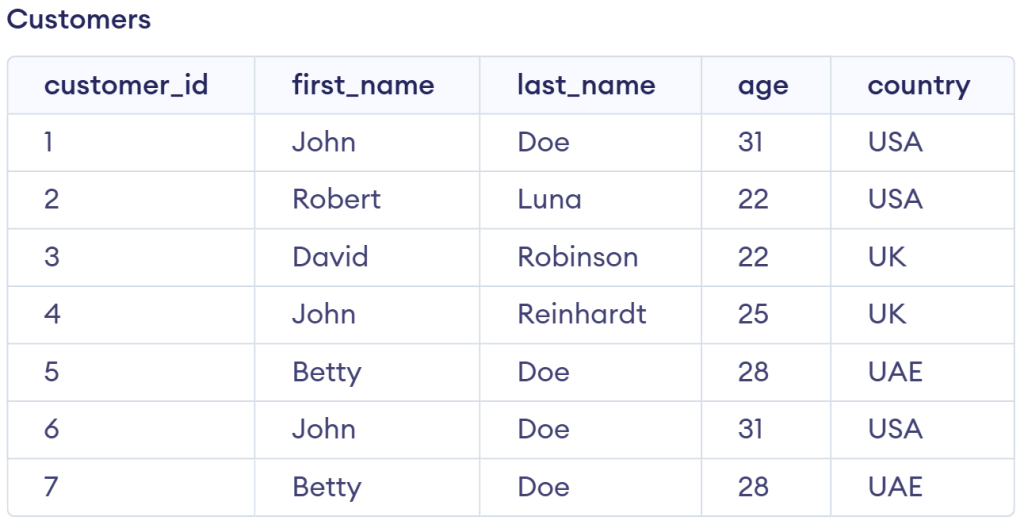
This table shows the identical rows with different customer_id’s. This allows us to demonstrate a couple of ways to delete the duplicate rows.
This method delete duplicate records in mysql in a table, by grouping the values that are duplicates together using GROUP BY, then filtering from the grouped data the duplicate values that have more than one occurrence using the “HAVING” clause to identify the duplicates. All duplicate values must have at least one unique value, such as the customer_id to use to identify which row to keep and which rows to delete.
The query selects the lowest customer_id for each set of duplicate rows, and deletes all rows whose customer_id does not appear in this set. This keeps one unique row per duplicate set, and deletes the other duplicates:
DELETE FROM Customers WHERE customer_id NOT IN ( SELECT MIN(customer_id) FROM Customers GROUP BY first_name, last_name, age, country );
This method relates to correlated subquery to delete duplicates, we are comparing each row against its duplicates based on the unique column and the criteria for duplicates (1_23251). The query deletes rows that have a pair that has the same data as this row, but with a smaller customer_id. This keeps the first row inserted, and removes any other duplicate:
DELETE FROM Customers AS c1
WHERE EXISTS (
SELECT 1
FROM Customers AS c2
WHERE c1.first_name = c2.first_name
AND c1.last_name = c2.last_name
AND c1.age = c2.age
AND c1.country = c2.country
AND c1.customer_id > c2.customer_id
);
For MySQL 8.0 and upward, we could use ROW_NUMBER() along with a CTE, it is clean and uses less resources to delete duplicates. The CTE orders the duplicate groups by customer_id and assigns each group a row number; basically if a row number is greater than 1 it is considered a duplicate row and is deleted. This is helpful for large datasets, and complex duplicate attributes:
WITH RankedCustomers AS (
SELECT customer_id, first_name, last_name, age, country,
ROW_NUMBER() OVER (PARTITION BY first_name, last_name, age, country ORDER BY customer_id) AS row_num
FROM Customers
)
DELETE FROM Customers
WHERE customer_id IN (
SELECT customer_id FROM RankedCustomers WHERE row_num > 1
);
Learn more about the size and table of postgreSQL, learn about How to Determine the Size of PostgreSQL Databases and Tables.
This is a method that takes all the unique rows and makes a new table by dropping the existing table. At the start, all the unique rows are appended into a temporary table that is created by grouping all columns (except the unique identifiers).
The original table is deleted and the temporary table is renamed to the name of the original. This method physically drops any duplicates in the table by rebuilding the entire table and is sometimes preferred when you want a really fresh start and you do not mind some downtime:
CREATE TABLE Customers_temp AS SELECT customer_id, first_name, last_name, age, country FROM Customers GROUP BY first_name, last_name, age, country; DROP TABLE Customers; ALTER TABLE Customers_temp RENAME TO Customers;
Removing duplicate rows in MySQL is important to maintain data integrity and get proper results when querying. There are plenty of ways duplicate rows were created including, user error, batch import, and bugs in software. Removing copies is good for performance and ensures you are giving proper outputs to your business. It is more critical when MySQL is supporting any reporting, anlytics, or user facing applications.
In this guide we provided several examples of finding and mysql remove duplicate rows. We have also tested each method on the sample Customers table so you know what you are doing and why. It doesn’t matter if you opted to use the basic GROUP BY and HAVING functions or the ridiculously more complicated ROW_NUMBER() with CTE, it worked for the appropriate MySQL version or if the dataset would fit in memory. Use what works for you and your organization to keep your queries outputting correct, clean, and consistent information.
Consider using Ultahost dedicated server hosting, which provides the control and security needed for a smooth database experience. With root access to your server, you can easily install and configure MySQL and set up triggers to automate your database tasks efficiently.
Duplicate rows usually occur due to repeated data imports, manual entry mistakes, or bugs in application logic.
Use GROUP BY with COUNT(\*) in a HAVING clause to identify values that appear more than once.
No, always create a backup before deleting rows to avoid accidental data loss.
Yes, but it’s less precise; using a unique column like customer\_id ensures safe and targeted deletions.
Using ROW\_NUMBER() with a CTE is efficient for large tables and offers better control over which duplicates to keep.
No, unless you define unique constraints or indexes, MySQL allows duplicate rows.
MySQL 8.0 and later versions support window functions, including ROW\_NUMBER().

MySQL has a range of available storage engines that c...
Managing databases is an important aspect of web hostin...
SQL Server Management Studio (SSMS) is a comprehensive,...
MySQL, one of the most popular relational database mana...
MySQL triggers are a powerful feature that allows autom...