
How to Install FFmpeg on Ubuntu 22.04
As a Ubuntu user, managing video and audio files can be...




Apache Spark offers a powerful open-source framework specifically designed for processing large datasets at scale. Its ability to distribute computations across clusters of computers makes it a popular choice for data scientists and engineers tackling complex data-intensive tasks. Spark’s efficiency and versatility make it ideal for various applications, including machine learning, graph processing, and real-time data analysis.
This comprehensive guide equips you with the knowledge to install Spark Ubuntu operating system. Whether you’re a seasoned data professional or just beginning your Spark journey, you’ll find clear, step-by-step instructions, helpful screenshots, and troubleshooting tips to ensure a smooth and successful installation process. Follow along to unlock the power of distributed computing and elevate your data processing capabilities with Spark on Ubuntu.
This section outlines the process of installing Spark on Ubuntu using pre-built binaries. This method offers a straightforward and efficient installation experience.
Step 1: Download Spark Binaries
To install Spark latest version on Ubuntu, visit the official Apache Spark downloads page and select the desired Spark release and package type (Pre-built for Apache Hadoop). Next, Copy the download link for the Spark binary compatible with your Ubuntu system architecture.
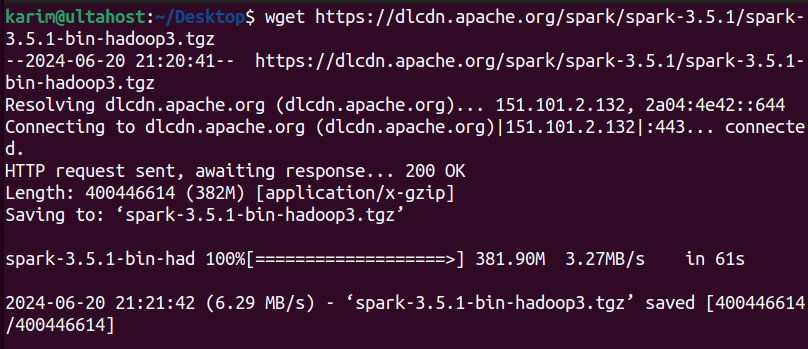
After that, you need to terminal and navigate to the directory where you want to download the file. Use the wget command followed by the copied download link to download the Spark binaries:
wget https://dlcdn.apache.org/spark/spark-3.5.1/spark-3.5.1-bin-hadoop3.tgz
Step 2: Extract the Archive
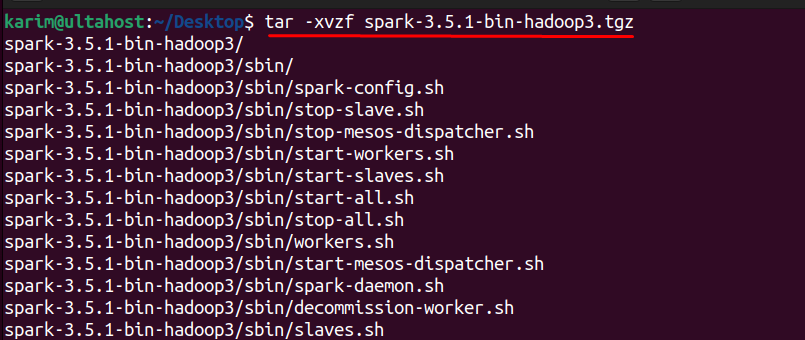
This downloads the file in .tgz format which can be extracted using the tar command:
tar -xvzf spark-3.5.1-bin-hadoop3.tgz
Step 3: Move the Extracted Folder to a Suitable Location
After extracting the archive, you’ll have a new folder named spark-3.5.1-bin-hadoop3 in your current directory. To make it easily accessible, let’s move this folder to a more suitable location, such as opt/spark. You can do this using the mv command:
sudo mv spark-3.5.1-bin-hadoop3 /opt/spark

This command moves the entire spark-3.5.1-bin-hadoop3 folder to /opt/, effectively Ubuntu Spark installation in a standard location.
Step 4: Set Environment Variables
For ease of use and to ensure Spark commands can be executed from anywhere in the terminal, we will set Linux environment variables. Open your .bashrc file using your preferred text editor (nano, vim, etc.):
nano ~/.bashrc
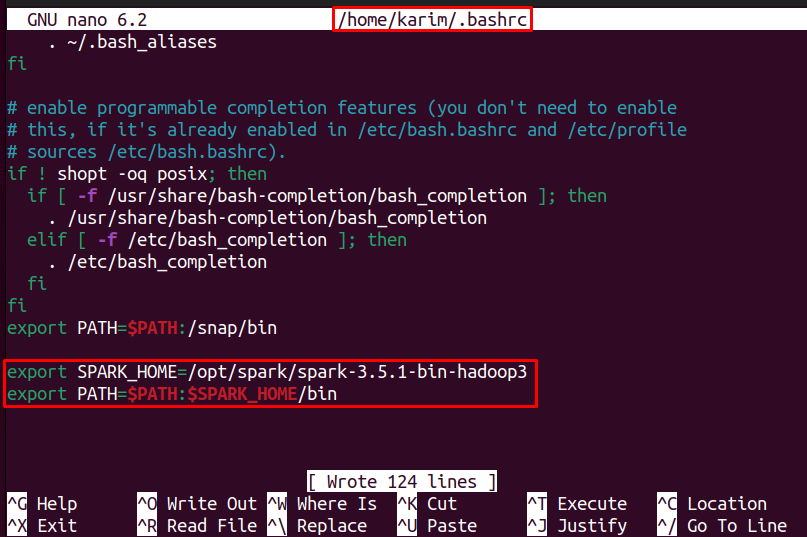
At the end of this file, add the following lines, ensuring you replace spark-3.5.1-bin-hadoop3 with your downloaded Spark version if different:
export SPARK_HOME=/opt/spark/spark-3.5.1-bin-hadoop3 export PATH=$PATH:$SPARK_HOME/bin
Save and close the file. To apply these changes to your current terminal session, run:
source ~/.bashrc

Step 5: Verify Spark Installation
Finally, let’s verify that Spark has been installed successfully. Open a new terminal window and type:
spark-shell --version
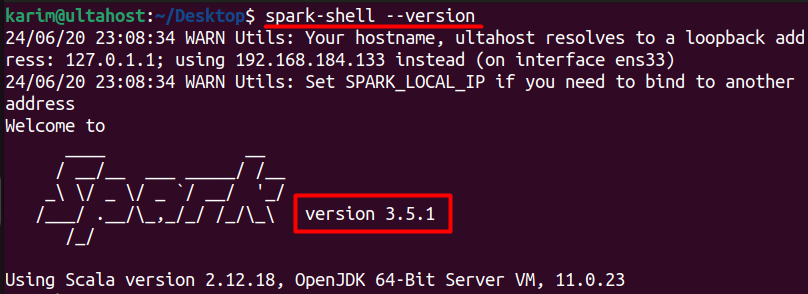
You should see the Spark version, confirming a successful Spark installation on Ubuntu!
Install Spark on Our Fast Ubuntu VPS
Experience the dependability of the world’s leading Linux distribution combined with the flexibility of a virtual server. Enjoy ultra-fast speeds and minimal latency.
Before we dive deeper into the installation process, let’s take a step back and explore the advantages of using Apache Spark. Spark has become a go-to tool for big data processing due to its unique set of benefits, including:
Ubuntu is a popular open-source operating system widely used in data science and engineering communities. Using Spark on Ubuntu offers several benefits, including:
Learn about How to Install Vagrant on Ubuntu.
Apache Spark is a powerful tool with a wide range of features that make it an ideal choice for big data processing. Some of the key features of Spark include:
While the installation process for Spark on Ubuntu is relatively straightforward, you may encounter some issues along the way. Here are some troubleshooting tips to help you overcome common installation issues:
This guide provided a concise walkthrough of installing Apache Spark on an Ubuntu operating system using pre-built binaries for a streamlined experience. We began by downloading the correct Spark release and package from the official website, followed by extracting the archive and moving it to the `/opt/` directory.
Importantly, we configured the necessary environment variables (`SPARK_HOME` and `PATH`) to ensure seamless Spark command execution from any location. This setup, verified by checking the Spark version, equips you to harness the power of distributed computing and tackle large-scale data processing tasks within the Spark ecosystem.
If you are a developer or starting your journey and trying to dive into the Linux operating system consider that you ensure your current setup can handle the demands of your specific needs. This is where you need a powerful and reliable platform like Ultahost. We provide affordable Linux VPS which helps to manage your server and dedicated resources for guaranteed speed and stability to perform your required task.
You can download Apache Spark from the official website: Apache Spark Downloads. Choose the latest version and the pre-built package for Hadoop.
Extract the downloaded tar file:
tar xvf spark-<version>-bin-hadoop<version>.tgz
Move it to the desired installation directory (e.g., /opt/spark):
sudo mv spark-<version>-bin-hadoop<version> /opt/spark
Add the following lines to your .bashrc or .profile file to set up the Spark environment variables:
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Then, source the file to apply the changes:
source ~/.bashrc
You can configure Spark by editing the spark-defaults.conf file located in the conf directory of your Spark installation. Here, you can set various configuration parameters such as executor memory, core settings, etc.