
How to Review Login Events in a Windows Serve...
Login events play a crucial role in maintaining the sec...




The robots.txt file is an important component for managing how search engines interact with your website. It provides instructions to web crawlers about which pages or files they can or cannot request from your website.
In this post, we will cover the process of setting up a robots.txt file on a Linux server covering everything from the basics to advanced configurations.
The robots.txt Linux file is part of the Robots Exclusion Protocol (REP) a standard used by websites to communicate with web crawlers and other web robots. The file is placed in the root directory of your website and contains directives that tell these robots which pages they are allowed to crawl and index.
Using a robots.txt file is essential for several reasons:
The robots.txt file uses a simple syntax with two main directives:
Here is a basic example:
User-agent: * Disallow: /private/
This example tells all web crawlers (denoted by *) not to crawl any pages under the /private/ directory.
To generate robots.txt files, access the server you need to install PuTTY on Windows system or connect to your Linux server using a secure shell (SSH) with the following command:
ssh username@server_ipaddress
Replace username with your username and server_ipaddress with the IP address of your server.

Use the cd command to change to the root directory of your website. For example, if your website is located in the /var/www/html the directory you would use:
cd /var/www/html

You can use any text editor like vi, nano, or gedit. For example to use nano open the terminal and type:
nano robots.txt
Write the rules according to your requirements. Here is an example:
User-Agent: ia_archiver Disallow: /terms.php User-Agent: * Allow: / Sitemap: https://ultahost.com/sitemap.xml
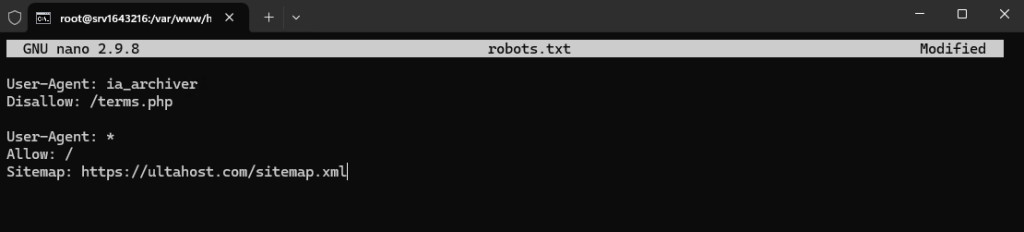
Save the file in the root directory of your website.
Setting Up robots.txt File on Our Linux Server!
Ultahost offers Linux hosting with NVMe SSD storage. Use our Linux VPS to generate robots.txt file to streamline your processes.
After creating the robots.txt file it is important to test it to ensure it works as expected. You can use online tools like Google Search Console or simply access the file directly in your browser:
https://ultahost.com/robots.txt

Following are some advanced configurations while creating a robots.txt file on the Linux server:
You can block specific user agents by specifying their names using robots.txt disallow directives:
User-agent: BadBot Disallow: /
This example blocks a bot named “BadBot” from crawling any part of your site.
You can allow specific paths while blocking others:
User-agent: * Disallow: /private/ Allow: /private/public-info/
This example blocks all crawlers from accessing the /private/ directory except for the /private/public-info/ subdirectory.
Some crawlers support the Crawl-delay directive which specifies the number of seconds to wait between requests:
User-agent: * Crawl-delay: 10
This example instructs crawlers to wait 10 seconds between requests.
You can specify the location of your sitemap in the robots.txt file:
Sitemap: http://yourwebsite.com/sitemap.xml
Following are some important notes during setting up the robots.txt file on the Linux server:
Setting up a robots.txt file on a Linux server is a straightforward process that can significantly impact how search engines interact with your site. By following the steps outlined in this guide you can create a robots.txt file that effectively manages web crawler access protects sensitive information and optimizes your site’s crawl budget.
Remember to test your robots.txt file regularly and update it as needed to reflect changes in your site’s structure or content strategy. With a well configured robots.txt file, you can ensure that your site is efficiently crawled and indexed by search engines improving your site’s visibility and performance.
Elevate your business with Ultahost NVMe VPS hosting that provides significantly faster data access speeds compared to traditional storage options. This means your website will load faster resulting in a smoother user experience and potentially higher conversion rates.
A robots.txt file tells search engines which pages they can or can’t access on your site.
It helps control what web crawlers can see and improves SEO by blocking unnecessary pages.
You can create it using a text editor like Nano or Vim and save it in your website’s root directory.
Place the robots.txt file in the root folder of your website usually /var/www/html/.
Yes, you can block all bots by adding User-agent: * and Disallow: / to your robots.txt file.
Use User-agent: * and Disallow: to let all bots crawl your entire site.
If you don’t have one search engines will crawl and index all accessible pages by default.