
How to Install Plesk on Linux
Plesk is a comprehensive web hosting control panel desi...




Hadoop enables the distributed processing of very large data sets across clusters of computers using algorithms and programming models as simple as possible. Ubuntu describes one of the most common Linux distributions well known for its straightforward nature. If proper guidance is provided, installing Hadoop on Ubuntu can be quite easy. Thus, this is a step-by-step article demonstrating the installation process of Hadoop on Ubuntu.
Due to issues concerning scalability and fault tolerance, Hadoop is widely accepted in the handling of big data. Hadoop has two main components consisting of storage and processing. The first is the Hadoop Distributed File System (HDFS) and the second is the MapReduce programming model which processes data in parallel across a distributed cluster.
Ubuntu provides a Linux interface which is easy to operate. Because of its stability and security, it is highly appreciated by developers and system administrators.
The following are the steps to install Hadoop on Ubuntu operating system:
Step 1: Updating System Repositories
When installing Hadoop on Ubuntu, updating the package lists ensures that you have the latest information about available software packages and their versions. This step is essential to ensure that when you proceed with installing Hadoop and its dependencies, you’re using the most up-to-date package information from the Ubuntu repositories. This helps in avoiding potential issues related to outdated package lists and ensures a smoother installation process.
sudo apt update
Step 2: Installing Java Development Kit (JDK)
The Java Development Kit (JDK) is essential for developing and running Java applications. Hadoop, being a Java-based framework, requires the JDK to be installed on the system to compile and run its Java code. By installing the default JDK package using this command, you ensure that the necessary Java development tools are available on your system, which are required for building and running Hadoop.
sudo apt install default-jdk
When you run this command, it will output information about the version of Java that is currently installed on your system. This information includes the version number of Java along with additional details such as the Java Runtime Environment (JRE) version and the Java Virtual Machine (JVM) version. Verifying the Java version is important to ensure compatibility with Hadoop, as certain versions of Hadoop may require specific versions of Java to function properly.
java -version

Step 3: Downloading Hadoop
After opening the browser, navigate to the official Hadoop website to open the Apache Hadoop website’s releases page. This page typically provides information about the various releases of Apache Hadoop, including the latest stable versions and any relevant release notes or documentation. It’s a resource where you can find the download links for different versions of Hadoop.
Next, copy the link address and execute the following command:
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.4.0/hadoop-3.4.0.tar.gz
By executing this command, you’re instructing wget to download the specified Hadoop distribution package from the provided URL. Once the download is complete, you’ll have the Hadoop distribution archive file available locally on your system. This archive file contains all the necessary files and directories required to install and configure Hadoop on your Ubuntu system.
Step 4: Extracting the Content
The downloaded file with be an archive file where you need to extract its content by executing the below command:
tar -xzvf hadoop-3.4.0.tar.gz
The -x option specifies extraction, the -z option indicates that the archive is compressed with gzip, the -v option enables verbose mode for detailed output, and the -f option specifies the filename of the archive to be processed.
After running this command, the contents of the Hadoop archive will be extracted and available in a directory named hadoop-3.4.0 in the current working directory. This directory will contain all the files and directories comprising the Hadoop distribution, which can then be further configured and utilized as needed.
Install Hadoop on Our Ubuntu VPS
Get the reliability of the world’s most popular Linux distro and the flexibility of a virtual server. Enjoy blazing-fast speeds and low latency.
Step 5: Moving the Extracted Hadoop Directory to the Installation Location
It is a common practice to organize Hadoop installations on Ubuntu systems. Moving the directory to /usr/local/hadoop ensures that Hadoop is installed in a standard location where it can be easily accessed and managed. After running this command, you’ll find the Hadoop installation directory located at /usr/local/hadoop, containing all the necessary files and directories for configuring and running Hadoop on your system.
sudo mv hadoop-3.4.0 /usr/local/hadoop

Step 6: Finding the Installed Java Path
This can be useful for obtaining the directory where Java is installed, which may be necessary for configuring Hadoop.
readlink -f /usr/bin/java | sed "s:bin/java::"

Step 7: Editing Hadoop Environment Configuration File
Next, you need to open the “hadoop-env.sh” file for editing. This allows you to modify environment variables and other configurations as needed to customize the behavior of your Hadoop installation. Using nano as the text editor provides a simple interface for making changes to the configuration file directly from the terminal.
sudo nano /usr/local/hadoop/hadoop-3.4.0/etc/hadoop/hadoop-env.sh
Then write this line inside hadoop-env.sh:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64/
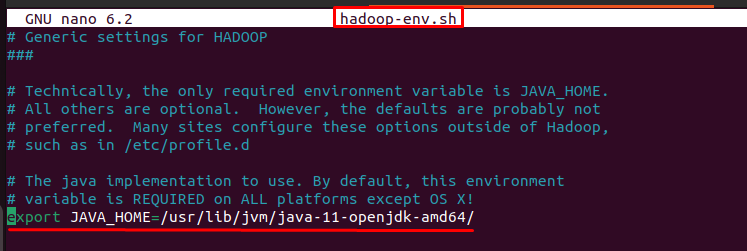
By including this command in the “hadoop-env.sh” file, you’re specifying the location of the Java installation that Hadoop should use. This is essential because Hadoop requires Java to be installed on the system and needs to know the location of the Java executable to run. Setting the JAVA_HOME environment variable ensures that Hadoop can locate the Java installation correctly and use it for its operation.
Read also How to Install Terraform on Ubuntu 22.04.
Furthermore, it sets the JAVA_HOME environment variable with the static address pointing to the installation directory of the Java Development Kit (JDK). To provide the dynamic location of the Java installation directory without hardcoding the path, you can execute:
export JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::")
This can be useful in scenarios where the location of the Java executable may vary across different systems. The command ensures that the JAVA_HOME environment variable always points to the correct Java installation directory, regardless of the specific path to the Java executable.
If you are not able to find these commands then you can use CTRL+W shortcut key to find this line as well.
Step 8:Verifying Hadoop Installation
Now, the installation of Hadoop is completed that you can verify using the below command:
/usr/local/hadoop/hadoop-3.4.0/bin/hadoop version
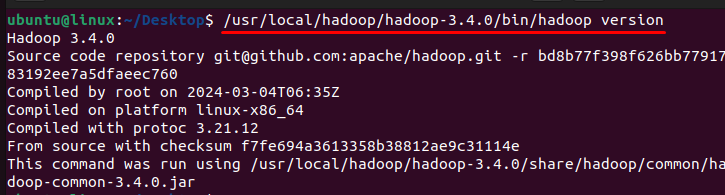
By executing this command, you are instructing Hadoop to output information about its version. This includes latest Hadoop installation on Ubuntu such as the version number, build information, and any other relevant metadata. Checking the version of Hadoop installed on the system is important for verifying the installation and ensuring compatibility with other software components or applications that rely on Hadoop.
Hadoop is a distributed processing technology that enables the processing of large datasets across clusters of computers using simple programming models. It consists of two main components: the Hadoop Distributed File System (HDFS) for storage and the MapReduce programming model for processing.
The installation process of Hadoop in Ubuntu has also been discussed in this guide. By following these instructions, users can quickly get up and running with Hadoop, unlocking its potential to transform their data workflows and drive insights that were previously unattainable.
Installing Hadoop on Ubuntu requires configuring a distributed system across multiple servers. For this Ultahost’s cheap Linux VPS hosting plans offer the perfect solution which provides root access and the ability to install software like Hadoop. These plans also offer the resources and flexibility to handle the demanding requirements of Hadoop.
Hadoop is an open-source framework used for distributed storage and processing of large datasets across clusters of computers using simple programming models.
Ubuntu 22.04 is a popular Linux distribution known for its stability, security, and ease of use. Installing Hadoop on Ubuntu 22.04 provides a reliable environment for managing big data workloads.
Before installing Hadoop on Ubuntu 22.04, ensure that you have Java installed and configured properly. Hadoop requires Java to run, so make sure you have Java Development Kit (JDK) installed on your system.
Yes, you can run Hadoop in a single-node setup on Ubuntu 22.04 for development and testing purposes. In a single-node setup, Hadoop runs all its daemons on a single machine, simulating a small-scale distributed environment.